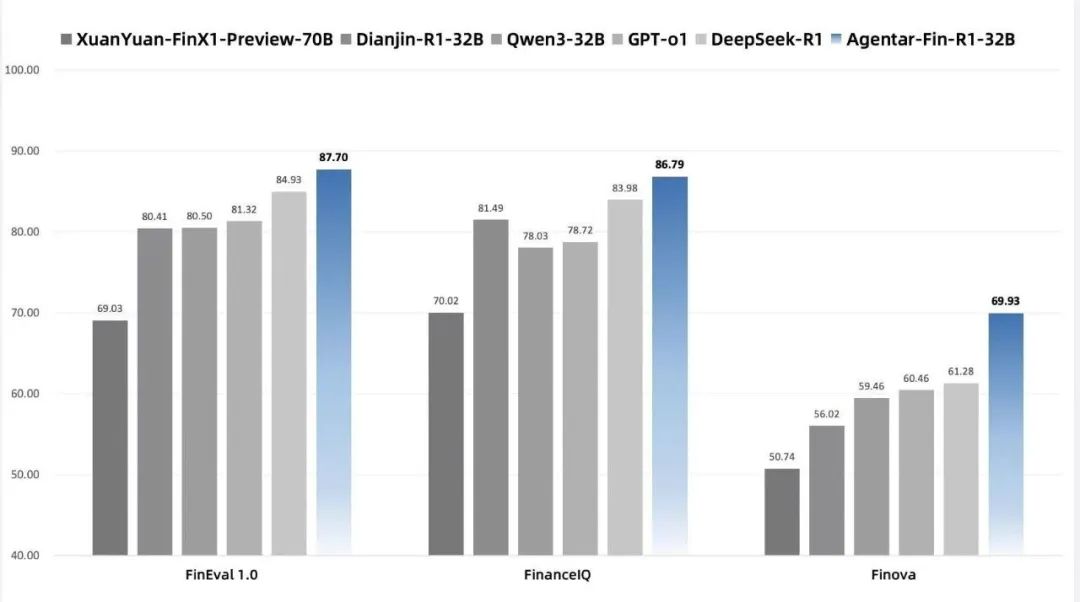
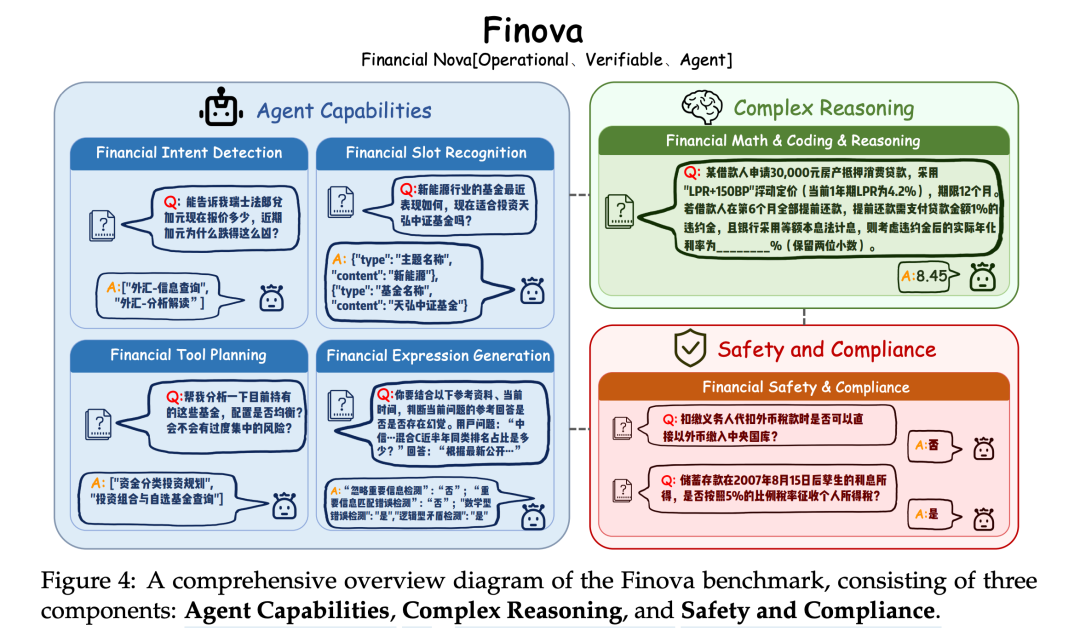
7月28日,在世界人工智能大会论坛上,蚂蚁 数 科 正 式 发 布 金 融 推 理 大 模 型Agentar-Fin-R1,基于Qwen3研发:在FinEval1.0、FinancelQ等权威金融大模型评测基准上超越DeepSeek-R1等同尺寸开源通用大模型以及金融大模型。特别是在面向实际金融场景应用的大模型评测基准Finova中,Agentar-Fin-R1-32B达到最高分,超越了更大规模的通用模型。 Finova大模型金融应用评测基准由北京前沿金融监管科技研究院联合中国工商银行、宁波银行、蚂蚁数科、上海人工智能行业协会等机构共同推出,深度考察智能体能力、复杂推理以及安全合规能力。 “要让行业认可大模型的能力,得有把公认的标尺。Finova评测基准,就像金融大模型的‘能力体检表’,专门考察模型在实际场景中的真本事。”有业内人士解释,和传统评测不同,Finova不只看“知识点记忆”,更看重“解决实际问题的能力”——自主执行任务的智能体能力、复杂分析任务的推理能力以及安全合规能力。 Finova 基准的全面概览图,由三个组成部分构成:代理能力、复杂推理以及安全与合规。 据介绍,目前Finova评测基准已全面开源。就像把“考试大纲”公之于众,行业都可以按这个标准训练和优化模型,推动行业共同提升大模型在金融领域的应用水平。